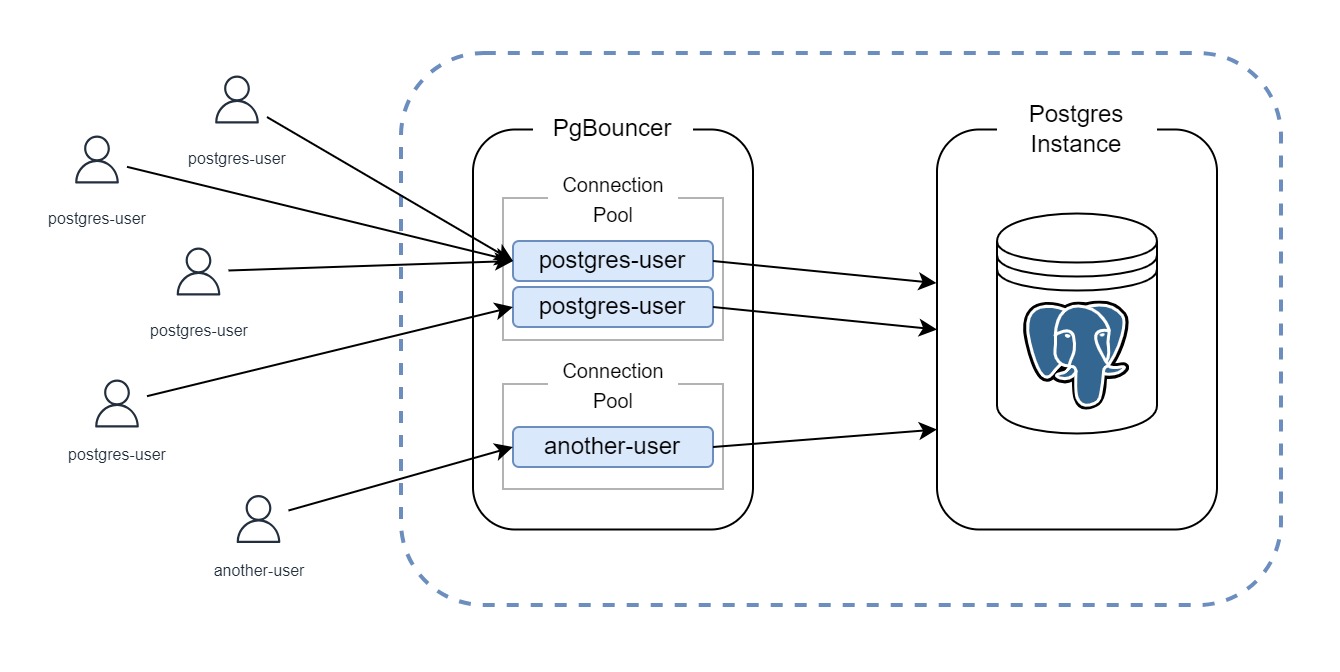
In the world of database management, PostgreSQL stands tall as a powerful and reliable open-source relational database system. However, as database workloads grow, efficient connection management becomes crucial for maintaining performance and scalability. This is where connection poolers like Pgbouncer come into play.
In this blog post, we’ll explore the setup and configuration of Pgbouncer — a lightweight connection pooler—for PostgreSQL on Amazon EC2 instances. Pgbouncer acts as an intermediary between your application and the database, efficiently managing database connections.
Prerequisites
Make sure you have followed the steps in our previous blog post, Setting up a highly available PostgreSQL Cluster with Patroni using Spilo Image, to set up PostgreSQL on your EC2 instances. We’ll be using the same instances for this blog post.
Why Use Pgbouncer?
Managing database connections can be resource-intensive. Each connection consumes memory on the database server. When your application requires numerous connections, this can lead to performance bottlenecks. Pgbouncer addresses this issue by pooling and reusing database connections, resulting in significant improvements in efficiency and scalability.
Before we dive into the technical details, let’s take a look at the configuration file and systemd unit file that will enable us to set up Pgbouncer for PostgreSQL on Fedora CoreOS.
The Configuration File
The following is the systemd unit configuration for our Pgbouncer service, which can be added to the Butane configuration file from the previous blog post:
The above configuration will run the Pgbouncer container, and expose the Pgbouncer service on port 6432. The Pgbouncer itself will connect to the PostgreSQL DB with the parameters we specified in DB_HOST, DB_NAME, and DB_PORT. Connections from the end-user to the Pgbouncer will be secured using TLS with the self-signed certificates generated with a script that can be found in our Github repository here.
On the first step, we run a script called prepare_pgbouncer_auth.sh. Here, we are creating a database user that will be used by Pgbouncer to verify whether incoming connections are allowed or not. The script is as follows:
First it waits until the PostgreSQL instance is ready to accept connections. Then it creates a database user called pgbouncer. The user pgbouncer is granted with a very limited set of privileges. It can only connect to the database and execute the get_auth function. This function is used by Pgbouncer to verify whether incoming connections are allowed or not.
After the script is successfully executed, we can specify the pgbouncer user as an AUTH_USER in the systemd unit configuration.
In the systemd unit configuration, we are specifying the AUTH_QUERY with the value SELECT username, password FROM pgbouncer.get_auth($1). This means that Pgbouncer will execute the pgbouncer.get_auth function with the username provided by the client. If the function returns a row, then the connection is allowed. Otherwise, the connection is rejected.
Then we have the STATS_USERS parameter. This parameter specifies the users that are allowed to retrieve statistics about the Pgbouncer instance, e.g SHOW STATS command. The information returned will be useful and can be used to monitor the Pgbouncer service. In our case we are using a user called stats_collector.
Finally we have AUTH_FILE. This parameter specifies the location of the userlist.txt file. This file usually contains the list of users and their passwords that are allowed to connect to the database. In our setup (which is a very simple setup), the file contains the following:
Users in this file are allowed to connect to Pgbouncer’s internal database pgbouncer and will not be queried against the pgbouncer.get_auth function. In addition, the user pgbouncer is used to authenticate against the database.
Now that we have covered the systemd unit configuration, we are ready to deploy the EC2 instances with our new configuration file. However, we still need to change an entry in our Security Group task. Since we are now using Pgbouncer on port 6432, we wouldn’t want to expose port 5432 that is used by the Postgres database. Instead, we will expose the port 6432. Here’s the updated version of the Security Group task in the network_conf-task.yml file:
We now have everything set up and ready to go. Let’s deploy the instances by using the same Ansible script from the previous blog post to deploy the instances.
Verifying the Connection Pooler
Once the instances are up and running, we can SSH into one of the instances and check the status of the Pgbouncer service by running the following command:
You should see a response similar to the following:
Now that we have verified that the Pgbouncer service is running, we can test the connection by connecting to the database using the psql command with postgres as the username and zalando as the (default) password:
Or you can also connect to the database pgbouncer as the stats_collector user to monitor the Pgbouncer statistics. The password of this user is defined in the userlist.txt file (In our case now it’s collecter_stats). We can do this by running the following command:
After entering the correct password, you should see a response similar to the following:
With that we have verified that the Pgbouncer service is running and that we can connect to the database using the Pgbouncer service.
Wrapping Up
In this blog post, we’ve explored the essential concept of using Pgbouncer, a connection pooler, to enhance the efficiency and scalability of your PostgreSQL database on EC2 instances. We’ve learned how to set up and configure Pgbouncer to act as a intermediary layer between your application and the database server, managing connections seamlessly.
By following the detailed steps and configurations outlined in this blog post, you’ve taken a significant step towards optimizing your PostgreSQL setup for high-performance and scalability. With Pgbouncer in place, you can confidently manage your database connections while maintaining a secure and efficient PostgreSQL environment.
We hope this guide has been informative and that it simplifies your journey in harnessing the full potential of PostgreSQL!

Farouq Abdurrahman ist Praktikant bei der Proventa GmbH und studiert Informatik. Sein Schwerpunkt liegt auf Cloud Computing. Er hat großes Interesse an der Digitalen Transformation und Cloud Computing. Aktuell beschäftigt er sich mit PostgreSQL Datenbanken in der Cloud.