In unserem vorherigen Blogbeiträgen, Setup eines hochverfügbaren Patroni PostgreSQL Clusters mit Spilo, haben wir den Weg zur Einrichtung eines hochverfügbaren PostgreSQL-Clusters, der von Patroni mit dem Spilo-Image verwaltet wird, begonnen. Wir haben gesehen, wie Patroni in Zusammenarbeit mit einem etcd Cluster PostgreSQL auf ein neues Niveau in Bezug auf Verfügbarkeit und automatisches Failover hebt. Aufbauend darauf wollen wir nun das nächste Kapitel in unserer Reise erkunden: das Backup und die Wiederherstellung eines hochverfügbaren PostgreSQL-Clusters mit einem S3-Bucket.
Warum ein S3 Bucket?
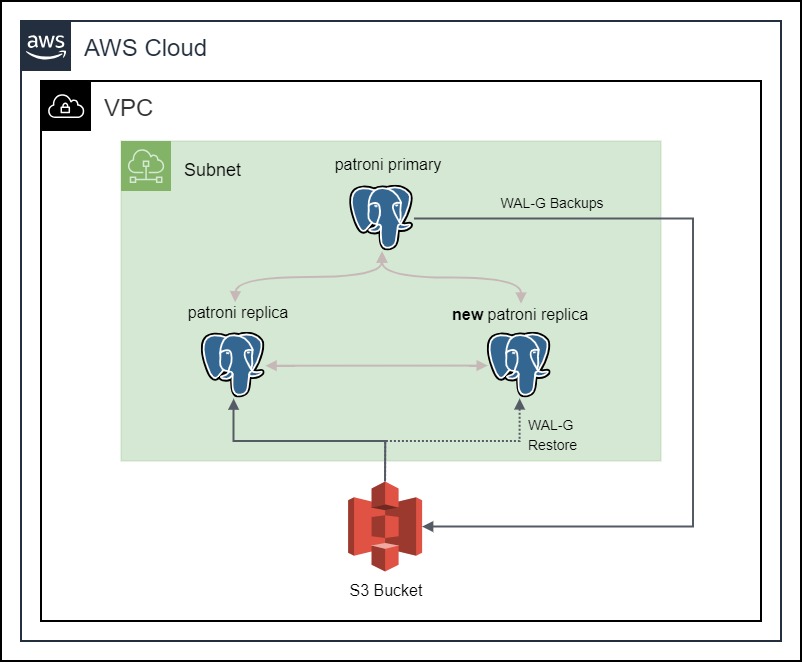
In einem hochverfügbaren PostgreSQL-Cluster ist es wichtig, ein Backup der Datenbank zu haben. Das Backup kann verwendet werden, um die Datenbank im Falle eines Ausfalls wiederherzustellen. Außerdem kann das Backup verwendet werden, um neue Replikate zu erstellen, anstatt die Daten direkt vom Primär-Node zu streamen. Dies ist nützlich, wenn der Primär-Node stark ausgelastet ist und wir ein neues Replikat erstellen wollen, ohne die Leistung des Primär-Node zu beeinträchtigen.
Das Backup kann in einem Dateisystem oder in einem S3 Bucket gespeichert werden. Der Vorteil eines S3 Buckets liegt in seiner hohen Verfügbarkeit und Haltbarkeit. Laut der AWS Documentation ist der Standard-S3 Bucket darauf ausgelegt, eine Beständigkeit von 99,999999999% und eine Verfügbarkeit von 99,99% der Objekte über ein Jahr hinweg zu bieten. Das bedeutet, dass der S3 Bucket hochverfügbar und langlebig ist. Außerdem ist er einfach einzurichten und zu konfigurieren, da Spilo eine Möglichkeit bietet, WAL-E / WAL-G Backups automatisch zu erstellen und in einem S3 Bucket zu speichern. Wir werden diese Funktion nutzen, um unsere Backups im S3 Bucket zu speichern.
Einrichten des S3-Buckets
Schauen wir uns nun an, wie wir einen S3 Bucket für unser PostgreSQL-Cluster einrichten können.
Der erste Schritt besteht darin, einen neuen S3 Bucket zu erstellen. Nennen wir ihn patroni-demo-bucket. Wir können die folgende Ansible-Aufgabe verwenden, um den S3 Bucket zu erstellen:
Der nächste Schritt besteht darin, eine neue IAM-Rolle zu erstellen, die von den EC2-Instanzen, auf denen das Spilo-Image läuft, verwendet wird, um auf den S3 bucket zuzugreifen. Die IAM-Rolle sollte spezifische Berechtigungen haben, um auf den S3 bucket zuzugreifen. Wir können die folgende Ansible-Aufgabe verwenden, um die IAM-Rolle und ihre Berechtigungen zu erstellen:
Beachte, dass wir den Parameter assume_role_policy_document verwenden, um anzugeben, auf welchen Ressourcen die IAM-Rolle angenommen werden kann. In unserem Fall werden wir die EC2-Instanzen verwenden, die das Spilo-Image ausführen. Außerdem verwenden wir den Parameter policy_json, um die Berechtigungen festzulegen, die die IAM-Rolle haben wird. In unserem Fall werden wir die Berechtigungen verwenden, die in der Datei patroni-wal-role-policy.json bereitgestellt werden. Die Berechtigungen in dieser Datei sind die minimal erforderlichen Berechtigungen, um auf den S3 bucket zuzugreifen. Hier sind die Links zu den Details des assume_role_policy_document und der patroni-wal-role-policy.json.
Anschließend können wir das Instance Profile verwenden, um die IAM-Rolle den EC2-Instanzen zuzuweisen, die das Spilo-Image ausführen. Wir können die Aufgabe Start Fedora CoreOS instances aus dem vorherigen Blogbeitrag nehmen und sie so aktualisieren, dass die IAM-Rolle den EC2-Instanzen zugewiesen wird. So sollte die aktualisierte Aufgabe aussehen:
Zusammenführung des S3-Buckets und Spilo
Nun wollen wir betrachten, wie wir den S3-Bucket und Spilo zusammenführen können. Wir können die systemd Unit-Datei aus dem vorherigen Blogbeitrag nehmen und sie modifizieren, um den S3 Bucket einzubeziehen. Die modifizierte systemd Unit-Datei sollte wie folgt aussehen:
Wir spezifizieren die Umgebungsvariablen AWS_REGION, WAL_S3_BUCKET und AWS_ROLE_ARN. Die AWS_REGION-Umgebungsvariable gibt die Region an, in der sich der S3-Bucket befindet. Die WAL_S3_BUCKET-Umgebungsvariable spezifiziert den Namen des S3 Buckets. Die AWS_ROLE_ARN-Umgebungsvariable gibt die ARN der IAM-Rolle an. Diese IAM-Rolle wird von den EC2-Instanzen verwendet, die das Spilo-Image ausführen, um auf den S3-Bucket zuzugreifen.
Danach können wir einfach das Ansible-Skript erneut ausführen, um die EC2-Instanzen bereitzustellen, die das Spilo-Image ausführen werden. Es wird automatisch WAL-G-Backups erstellen und im S3-Bucket speichern. Lassen Sie das Spilo-Image einige Minuten laufen, und dann können wir überprüfen, ob die Backups im S3-Bucket gespeichert werden.
Überprüfung der WAL-Backups im S3-Bucket
Nun wollen wir prüfen, ob die Backups tatsächlich im S3-Bucket gespeichert werden. Dazu navigieren wir in der AWS-Konsole zum Abschnitt S3 Bucket und wählen den patroni-demo-bucket S3-Bucket aus. Wir sollten einen neuen Ordner namens spilo im S3-Bucket sehen. Der Ordner sollte einen Unterordner mit dem Namen unseres Patroni-Clusters enthalten, und in diesem Ordner sollten wir die WAL-G-Backups sehen. Wir können dies auch mit der AWS-CLI überprüfen, indem wir den folgenden Befehl in unserem Terminal ausführen:
Die Ausgabe sollte wie folgt aussehen:
Damit können wir sehen, dass die Backups im S3-Bucket gespeichert werden.
Zusammenfassung
Wir haben den Prozess der Erstellung von Backups für ein hochverfügbares PostgreSQL-Cluster unter Verwendung eines S3 Buckets untersucht. Diese Methode bietet den Vorteil, hohe Verfügbarkeit und Dauerhaftigkeit der Backups sicherzustellen. Wir haben die Schritte zur Einrichtung des S3-Buckets, zur Erstellung einer IAM-Rolle mit den notwendigen Berechtigungen und zur Integration mit dem Spilo-Image behandelt.
Durch Befolgen dieser Schritte können Sie Ihre PostgreSQL-Daten zuverlässig sichern und auf Disaster-Recovery-Szenarien vorbereitet sein. Die Speicherung von Backups in einem S3-Bucket bietet eine zuverlässige und robuste Lösung zum Schutz Ihrer kritischen Datenbankdaten. Wir hoffen, dass dieser Leitfaden informativ war und Ihnen bei der Implementierung effektiver Backup-Strategien für Ihr PostgreSQL-Cluster hilft.

Farouq Abdurrahman ist Praktikant bei der Proventa GmbH und studiert Informatik. Sein Schwerpunkt liegt auf Cloud Computing. Er hat großes Interesse an der Digitalen Transformation und Cloud Computing. Aktuell beschäftigt er sich mit PostgreSQL Datenbanken in der Cloud.