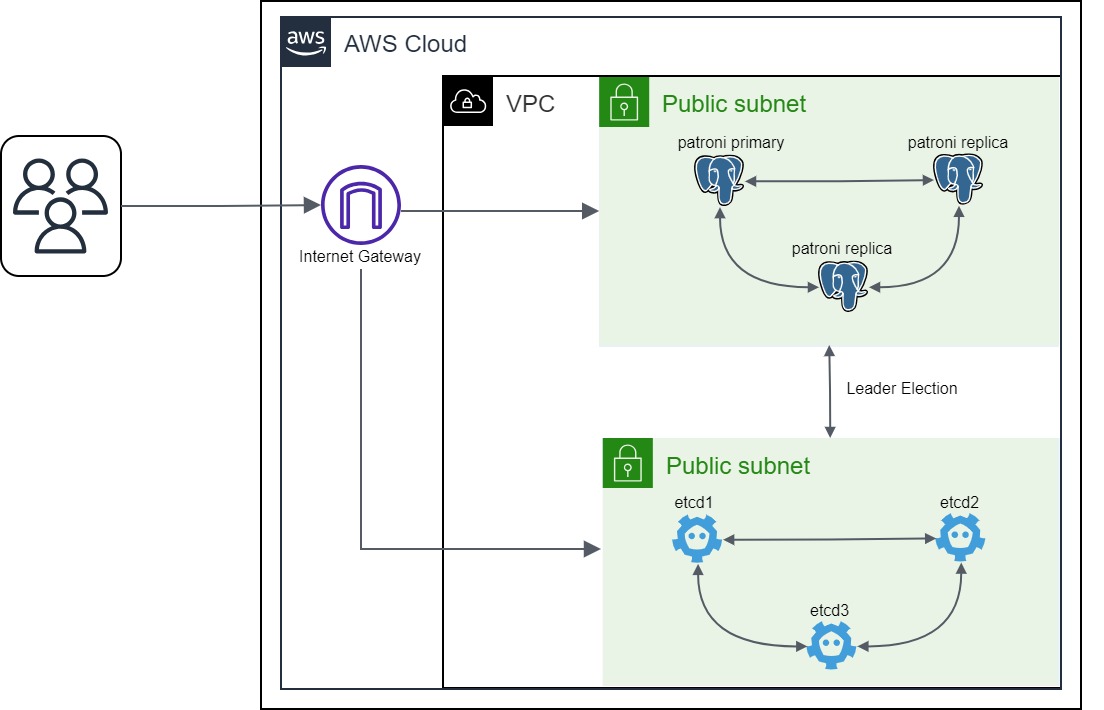
In der Welt moderner datengetriebener Anwendungen ist eine zuverlässige und verfügbare Datenbank ein Muss. Hier kommen Patroni und Spilo ins Spiel. Patroni ist eine Open-Source-Lösung zur Verwaltung hochverfügbarer PostgreSQL-Cluster, und Spilo ist ein Container-Image, das PostgreSQL und Patroni kombiniert und so die Bereitstellung fehlertoleranter Datenbank-Setups vereinfacht. Um diese Widerstandsfähigkeit zu erreichen, nutzt Patroni eine externe Komponente, die eine entscheidende Rolle spielt: einen verteilten Configuration Store. Diese Komponente ist für die Speicherung des Cluster-Zustands und die Koordinierung der Aktionen der verschiedenen Nodes verantwortlich. In diesem Blogbeitrag werden wir untersuchen, wie man einen Patroni-Cluster mit Spilo und etcd als verteilten Configuration Store einrichtet.
Voraussetzungen
Bevor wir beginnen, stellen Sie sicher, dass Sie dem vorherigen Blogbeitrag Aufbau eines hochverfügbaren etcd-Clusters auf AWS gefolgt sind. Wir werden den dort erstellten etcd-Cluster als verteilten Configuration Store für unseren Patroni-Cluster verwenden.
Einrichten des Patroni-Clusters
Wir werden das Spilo Image verwenden, um unseren Patroni-Cluster einzurichten. Spilo ist ein Container-Image, das PostgreSQL und Patroni kombiniert und so die Bereitstellung fehlertoleranter Datenbank-Setups vereinfacht. Das Spilo-Image basiert auf dem offiziellen PostgreSQL-Image und fügt Patroni und WAL-E/WAL-G hinzu. WAL-E und WAL-G sind Tools, die bei der kontinuierlichen Archivierung von PostgreSQL WAL-Dateien und Base-Backups helfen. Sie werden verwendet, um die Backup- und Restore-Funktionalität zu implementieren.
Da wir Fedora CoreOS verwenden, werden wir eine Butane-Datei erstellen, um den Patroni-Cluster zu konfigurieren. Die Butane-Datei wird die Konfiguration für das Spilo-Image enthalten, einschließlich der Konfiguration für den etcd-Cluster. Die Butane-Datei wird verwendet, um eine Ignition-Konfiguration zu erstellen, die zur Bereitstellung des Patroni-Clusters verwendet wird.
Erstellen eines rootless Users zum Ausführen des Spilo-Containers
Hier erstellen wir einen Benutzer namens patroni-user. Dieser Benutzer wird verwendet, um den Spilo-Container auszuführen. Dieser Benutzer ist keiner Gruppe zugeordnet und hat daher keine Root-Privilegien.
Notwendige Dateien in der VM mounten
Hier fügen wir die folgenden Dateien von der lokalen Maschine zu den EC2-Instanzen hinzu:
/etc/patroni-env: Diese Datei enthält die Umgebungsvariablen, die vom Spilo-Container verwendet werden./etc/ssl/self-certs/proventa-root-ca.pem: Diese Datei enthält das Root-CA-Zertifikat des etcd-Clusters./etc/ssl/self-certs/proventa-gencert-config.json: Diese Datei enthält die Konfiguration zur Generierung des Client-Zertifikats für den Spilo-Container./etc/ssl/self-certs/proventa-root-ca-key.pem: Diese Datei enthält den Private Keyl des Root-CA-Zertifikats des etcd-Clusters./usr/local/bin/generate-client-cert.sh: Diese Datei enthält das Skript, das zur Generierung des Client-Zertifikats für den Spilo-Container verwendet wird.
Diese Datei enthält das Skript, das zur Generierung des Client-Zertifikats für den Spilo-Container verwendet wird.
Für detailliertere Informationen zu den Dateien besuchen Sie bitte unser Github Repository.
Erstellen der Konfiguration für den Spilo-Container
Hier erstellen wir eine systemd Unit-Datei für den Spilo-Container. Die Unit-Datei wird verwendet, um den Spilo-Container als systemd-Dienst auszuführen. Die Unit-Datei enthält viele Attribute, aber lassen Sie uns uns auf den podman-Befehl konzentrieren, der im Abschnitt ExecStart ausgeführt wird. Dieser Befehl wird verwendet, um den Spilo-Container zu starten. Der Befehl hat die folgenden Flags und Cases:
Dies ist der Pfad zum Verzeichnis, das zur Speicherung der Daten des PostgreSQL-Clusters verwendet wird. Standardmäßig werden die Daten in /home/postgres/pgdata innerhalb des Containers gespeichert. Wir werden dieses Verzeichnis in das $/patroni-Verzeichnis auf der Host-Maschine einbinden. Ein weiterer Anwendungsfall, bei dem dies nützlich sein kann, ist, wenn Sie ein zusätzliches oder externes EBS-Volume zur Speicherung der Daten des PostgreSQL-Clusters verwenden möchten. Die Volumes können dann so konfiguriert werden, dass die Daten nicht verloren gehen, wenn die EC2-Instanz beendet wird.
Dies ist der Pfad zum Verzeichnis, das die Zertifikate des etcd-Clusters enthält.
Dies ist der Name des Clusters. Dieser Name wird verwendet, um den Patroni-Cluster im etcd-Cluster zu identifizieren.
Dies ist die Version von PostgreSQL, die vom Spilo-Container verwendet wird.
Dies ist das Protokoll, das für die Verbindung zum etcd-Cluster verwendet wird.
Dies ist die Liste der etcd-Hosts, die vom Patroni-Cluster verwendet werden. Die Liste der Hosts ist in der Umgebungsvariable „ETCD_HOSTS“ gespeichert.
Dies ist der Pfad zum Root-CA-Zertifikat des etcd-Clusters.
Dies ist der Pfad zum Client-Zertifikat.
Dies ist der Pfad zum Private Key des Client-Zertifikats.
Dies ist der Name des Spilo-Images, das verwendet wird, um den Spilo-Container auszuführen. In diesem Fall verwenden wir das spilo-15 Image in der Version 3.0-p1.
Beachten Sie, dass wir ETCD3 anstelle von ETCD verwenden. Dies liegt daran, dass unser etcd-Cluster Version 3 der etcd-API verwendet. Wenn Sie jedoch einen etcd-Cluster verwenden, der Version 2 der etcd-API nutzt, sollten Sie ETCD verwenden.
Bereitstellen des Patroni-Clusters auf einer EC2-Instanz
Nachdem wir die Butane-Datei konfiguriert haben, können wir sie verwenden, um eine Ignition-Konfiguration zu erstellen. Die Ignition-Konfiguration wird verwendet, um die EC2-Instanz bereitzustellen, auf der der Patroni-Cluster laufen wird. Um die Ignition-Konfiguration zu erstellen, führen Sie den folgenden Befehl aus:
Bevor wir eine EC2-Instanz für unseren Patroni-Cluster bereitstellen können, müssen wir die IP-Adressen des etcd-Clusters kennen. Um die IP-Adressen des etcd-Clusters zu erhalten, können wir die folgende Aufgabe innerhalb eines Ansible-Playbooks ausführen:
Die Datei ip_addresses_template.j2 enthält Folgendes:
Die Datei ip_addresses_template.j2 ist ein Jinja2-Template, das verwendet wird, um die patroni-env-Datei zu erstellen. Die patroni-env-Datei wird die IP-Adressen des etcd-Clusters enthalten, die zur Identifizierung des etcd-Clusters verwendet werden. Die patroni-env-Datei enthält Folgendes:
Eine weitere Sache, die vorbereitet werden muss, ist die Sicherheitsgruppe, die von der EC2-Instanz verwendet wird. Die Sicherheitsgruppe sollte den folgenden eingehenden Datenverkehr zulassen:
Wir können die folgende Ansible-Aufgabe verwenden, um eine Sicherheitsgruppe für den Patroni-Cluster bereitzustellen:
Nachdem wir nun die IP-Adressen des etcd-Clusters und die Sicherheitsgruppe für den Patroni-Cluster haben, können wir eine EC2-Instanz für unseren Patroni-Cluster bereitstellen. Um die EC2-Instanz bereitzustellen, können wir die folgende Aufgabe innerhalb eines Ansible-Playbooks ausführen:
Der Einfachheit halber konfigurieren wir die Security Group so, dass sie Verbindungen von überall auf Port 5432 zulässt, damit wir uns von unserem lokalen Rechner aus mit dem PostgreSQL-Cluster verbinden können. Daher verwenden wir ein öffentliches Subnetz für den Patroni-Cluster. Dies liegt daran, dass wir in der Lage sein wollen, uns von unserem lokalen Rechner aus mit der PostgreSQL-Datenbank zu verbinden. In einer realen Produktionsumgebung würden Sie ein privates Subnetz für den Patroni-Cluster verwenden.
Überprüfen des Patroni-Clusters
Nachdem wir den Patroni-Cluster bereitgestellt haben, können wir uns damit verbinden. Um eine Verbindung zum Patroni-Cluster herzustellen, können wir den folgenden Befehl ausführen:
Wenn die Instanz gerade erst bereitgestellt wurde, kann es einige Minuten dauern, bis die Maschine bereit ist, SSH-Verbindungen zu akzeptieren und den Spilo-Container zu starten. Bitte warten Sie daher einige Minuten.
Sobald Sie mit der EC2-Instanz verbunden sind, können Sie den folgenden Befehl ausführen, um den Status des Spilo-Containers zu überprüfen:
Wenn Sie einen laufenden Container mit dem Namen „patroni-container“ finden, dann läuft der Spilo-Container. Jetzt können wir den Status des Patroni-Clusters überprüfen, indem wir den folgenden Befehl ausführen:
Die Ausgabe sollte in etwa wie folgt aussehen:
Die Ausgabe zeigt, dass wir einen Patroni-Cluster mit einem Master-Node und zwei Replica-Nodes haben. Der Master-Node läuft auf node1 und die Replica-Nodes laufen auf node2 und node3. Die Ausgabe zeigt auch, dass die Replikation einwandfrei funktioniert, da der Lag 0 beträgt.
Zusammenfassung
Herzlichen Glückwunsch! Sie haben erfolgreich ein hochverfügbares PostgreSQL mit Patroni unter Verwendung des Spilo-Images auf AWS EC2-Instanzen eingerichtet. Ihre PostgreSQL-Datenbanken laufen nun in einer fehlertoleranten Konfiguration. Wir hoffen, dass dieser Blog Ihnen beim Aufbau zuverlässiger und hochverfügbarer Anwendungen mit PostgreSQL hilft. Bleiben Sie dran für die kommenden Blogbeiträge, in denen wir mehr über Lastverteilung und Backups für PostgreSQL erkunden werden und… wie immer, bleiben Sie neugierig und erkunden Sie weiterhin die sich ständig weiterentwickelnde Welt der Technologie.

Farouq Abdurrahman ist Praktikant bei der Proventa GmbH und studiert Informatik. Sein Schwerpunkt liegt auf Cloud Computing. Er hat großes Interesse an der Digitalen Transformation und Cloud Computing. Aktuell beschäftigt er sich mit PostgreSQL Datenbanken in der Cloud.