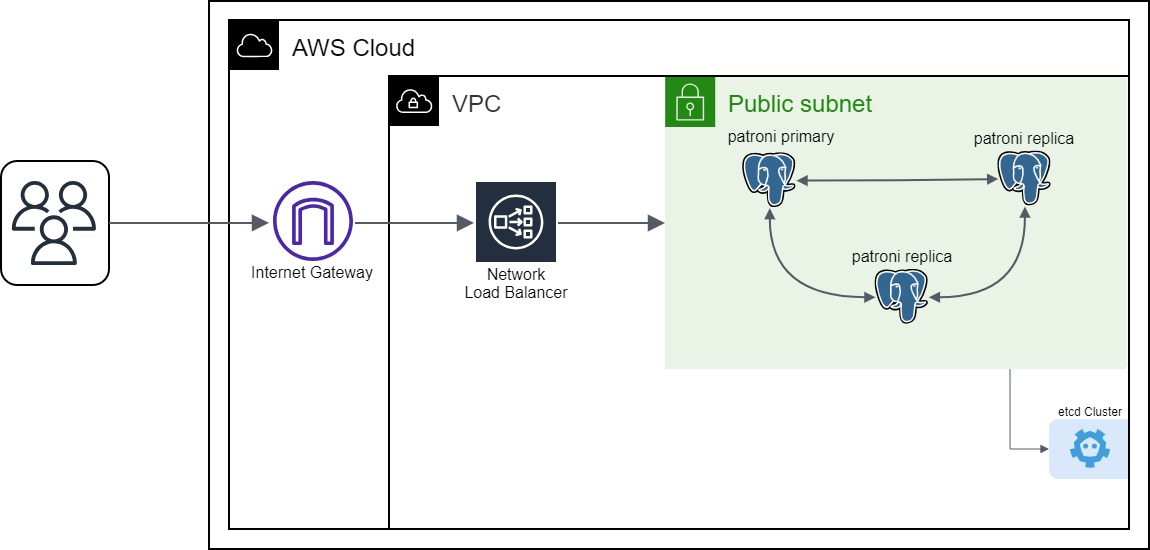
In unseren früheren Blogbeiträgen haben wir untersucht, wie man einen starken und zuverlässigen PostgreSQL-Cluster mit Patroni und dem Spilo-Container-Image erstellt. Wir haben auch Themen wie Connection Pooling für PostgreSQL und die Verwendung von S3-Buckets für Backup und Recovery behandelt, die alle die Zuverlässigkeit und Verfügbarkeit von PostgreSQL erhöht haben. Lassen Sie uns nun in den nächsten Teil unserer Reise eintauchen: Load Balancing.
Warum Load Balancing?

In einem hochverfügbaren PostgreSQL-Cluster ist der Load Balancer ein unverzichtbares Feature. Es gibt viele Möglichkeiten, wie wir den Load Balancer nutzen können.
Eine Möglichkeit ist die Verteilung des Datenverkehrs auf die Clusterknoten. Der Load Balancer kann so konfiguriert werden, dass er den Lese-Traffic auf alle Nodes des Clusters verteilt und den Schreib-Traffic auf den primären Node.
In unserem Fall werden wir die Replikate jedoch als Standby-Replikate und nicht als aktive Replikate verwenden. Das bedeutet, dass die Replikate nicht für eingehende Anforderungen verwendet werden, sondern eher als Failover- Node, falls der primäre Node ausfällt.
Die andere Möglichkeit besteht darin, den Load Balancer zu verwenden, um den primären Node zu bestimmen, an den die eingehenden Anforderungen weitergeleitet werden können. Wenn der primäre Node ausfällt, kann der Load Balancer automatisch entscheiden, welcher Node der neue primäre Node ist und die Anfragen an diesen Node weiterleiten. Dies ist der Ansatz, den wir verwenden werden.
Einrichten des Load Balancers
Sehen wir uns nun an, wie wir einen Load Balancer für unseren PostgreSQL-Cluster einrichten können. Zu diesem Zweck werden wir den AWS Network Load Balancer verwenden.
Der erste Schritt besteht darin, eine neue Target Group zu erstellen. Die Target Group ist eine Gruppe von Instanzen, die den Datenverkehr vom Load Balancer erhalten soll. In unserem Fall wird die Target Group die Instanzen unseres PostgreSQL-Clusters enthalten. Wir erstellen eine neue Target Group mit dem Namen patroni-tg und fügen die Instanzen unseres PostgreSQL-Clusters hinzu. Wir können den folgenden Ansible-Task verwenden, um die Zielgruppe zu erstellen:
Mit dem Parameter health_check_port geben wir den Port an, an dem die Health-Check-Prüfung durchgeführt werden soll. In unserem Fall verwenden wir den Health-Check-Endpunkt, der von Patroni bereitgestellt wird. Der Health-Check-Endpunkt ist auf Port 8008 verfügbar. Der Parameter successful_response_codes gibt die Antwortcodes an, die als erfolgreich angesehen werden. In unserem Fall leiten wir den Datenverkehr nur an den primären Node weiter, so dass wir nur den Antwortcode 200 als erfolgreich betrachten. Die Replikationsknoten geben den Antwortcode 503 zurück, was bedeutet, dass der Knoten nicht für den Empfang von Datenverkehr verfügbar ist.
Beachten Sie, dass wir in diesem Fall HTTP als Health-Check-Protokoll verwenden, da der von Patroni bereitgestellte Health-Check-Endpunkt ein HTTP-Endpunkt ist. Wenn Sie HTTPS als Health-Check-Protokoll verwenden, sollten Sie auch HTTPS im Parameter health_check_protocol angeben.
Der nächste Schritt ist die Erstellung eines neuen Load Balancers. Wir erstellen einen neuen Load Balancer mit dem Namen patroni-nlb und fügen ihm die Zielgruppe patroni-tg hinzu. Wir können den folgenden Ansible-Task verwenden, um den Load Balancer zu erstellen:
Mit dem Parameter subnets geben wir die Subnetze an, in denen der Load Balancer erstellt werden soll. In unserem Fall werden wir das Subnetz verwenden, in dem unser PostgreSQL-Cluster läuft. Mit dem Parameter listeners geben wir den Port an, auf dem der Load Balancer auf eingehende Anfragen wartet. In unserem Fall verwenden wir Port 6432, den Port für den PgBouncer. Außerdem geben wir die Zielgruppe an, die die eingehenden Anfragen erhalten soll. In unserem Fall verwenden wir die Zielgruppe patroni-tg, die wir im vorherigen Schritt erstellt haben.
Dem Load Balancer wird ein DNS-Name zugewiesen. Da wir den Load Balancer in einem öffentlichen Subnetz einsetzen, wird der DNS-Name öffentlich zugänglich sein. Wir können den DNS-Namen verwenden, um uns mit dem PostgreSQL-Cluster (über den PgBouncer) zu verbinden. Um den DNS-Namen des Load Balancers zu erhalten, können wir zur AWS-Konsole navigieren und den Load Balancer auswählen oder den folgenden Befehl in Ihrem Terminal verwenden:
Die Ausgabe sollte folgendermaßen aussehen:
Jetzt können wir uns über den PgBouncer mit der Postgres-Datenbank verbinden, indem wir postgres als Benutzernamen und zalando (Standardpasswort) als Passwort verwenden, indem wir den folgenden Befehl ausführen:
Nachdem Sie das richtige Passwort eingegeben haben, werden Sie mit dem PostgreSQL-Cluster verbunden:
Zusammenfassung
Zusammenfassend lässt sich sagen, dass wir erfolgreich einen Load Balancer für unseren PostgreSQL-Cluster eingerichtet haben. Unser Ansatz konzentriert sich auf die Verwendung eines Netzwerk-Load-Balancers, der das Routing des Datenverkehrs automatisch verwaltet. Dies erhöht die Ausfallsicherheit des Clusters und ermöglicht es, den Datenverkehr auch dann zu bewältigen, wenn ein Node Probleme hat. Wir haben auch gesehen, wie wir den Load Balancer nutzen können, um uns mit dem PostgreSQL-Cluster zu verbinden. Jetzt ist Ihr PostgreSQL-Cluster auf alle Herausforderungen, die auftreten können, gut vorbereitet. Vielen Dank, dass Sie uns auf dieser Reise begleitet haben, und wir hoffen, dass Sie unsere Blogbeiträge hilfreich fanden!

Farouq Abdurrahman ist Praktikant bei der Proventa GmbH und studiert Informatik. Sein Schwerpunkt liegt auf Cloud Computing. Er hat großes Interesse an der Digitalen Transformation und Cloud Computing. Aktuell beschäftigt er sich mit PostgreSQL Datenbanken in der Cloud.